
AI 時代的新型態攻擊:麥肯錫內部 AI 平台遭自主駭客 Agent 2 小時全面入侵
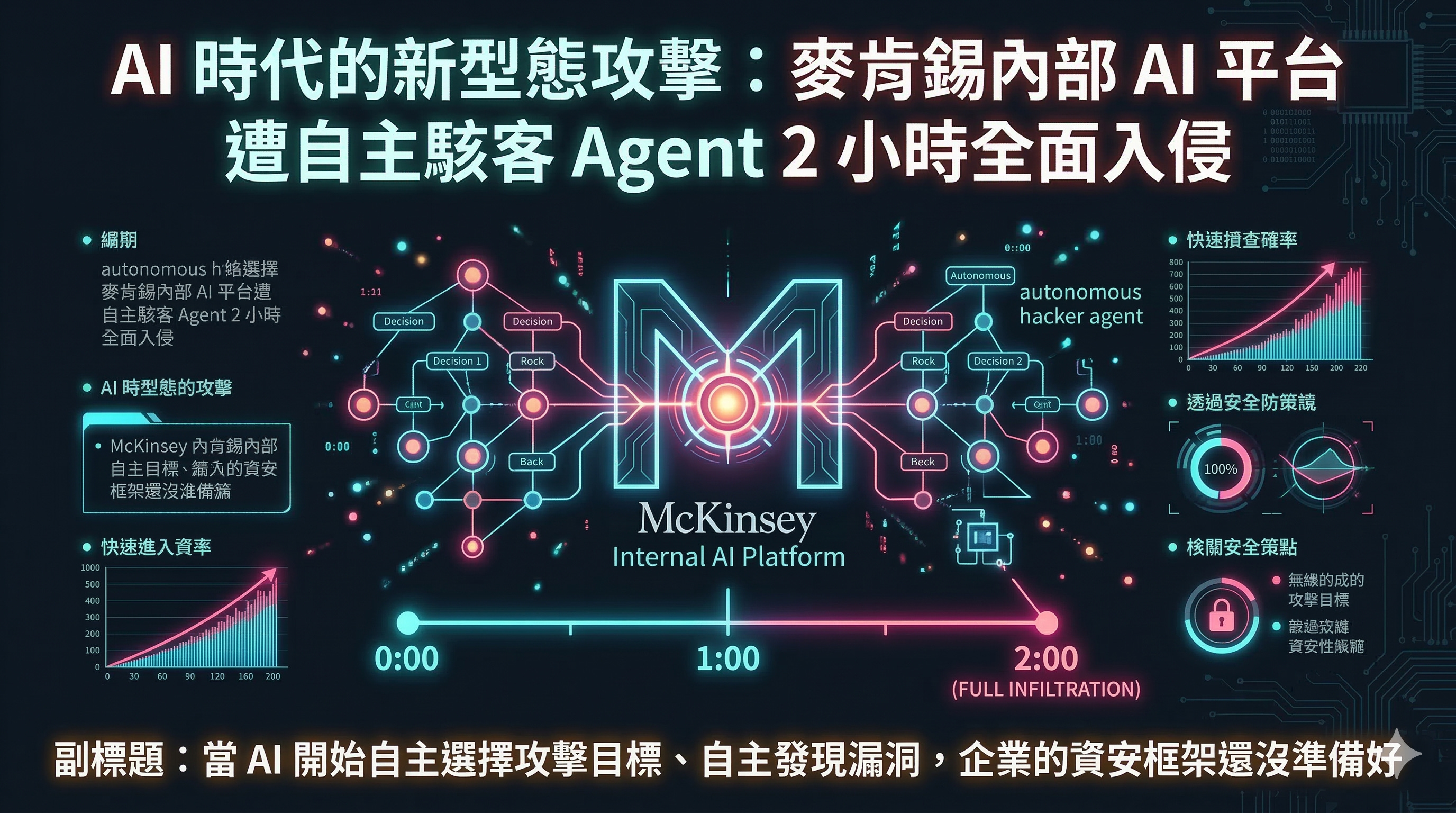
麥肯錫內部 AI 平台「Lilli」最近在紅隊測試中,被安全新創 CodeWall 釋出的自主駭客 Agent,在「無帳號、無人為介入」情況下,僅用 2 小時就拿下生產資料庫完整讀寫權限,暴露 4,650 萬則對話、72.8 萬份檔案與 5.7 萬名員工帳號。

1|TL;DR(3-Bullet Summary)
發生了什麼:資安公司 CodeWall 的自主攻擊 Agent,在無任何內部憑證的情況下,於 2 小時內透過 SQL Injection 取得麥肯錫 AI 平台 Lilli 的完整資料庫讀寫權限,含 4,650 萬筆對話紀錄、72.8 萬份文件,以及所有 System Prompt 配置。
為什麼重要:這不是一間新創公司的小疏失——麥肯錫擁有世界級資安團隊,Lilli 已上線超過兩年。此事件揭示的核心問題是:AI 的 Prompt 層(指令層)已成為企業最高價值、最少防護的攻擊面,而絕大多數組織連這個問題的存在都沒意識到。
你該怎麼想:AI 資安不能再用傳統 IT 資安思維處理。企業必須把 System Prompt 視同程式碼,納入版本控管、存取稽核、完整性監控。同時,AI Agent 用於攻擊的時代已提前到來,「持續自動化滲透測試」將成為標配,而非選配。
2|背景脈絡(Context)
麥肯錫的 Lilli 是企業內部 AI 平台的標竿案例之一。2023 年上線,以 1945 年麥肯錫第一位女性員工命名,供全球 43,000+ 員工使用,功能涵蓋企業知識庫問答、文件分析、策略研究 RAG 等。使用率超過 70%,每月處理逾 50 萬次提問—這是一個真正在生產環境大規模運行的企業 AI 系統,不是 PoC,不是 Demo。
CodeWall 是一家開發「自主攻擊型資安 Agent」的新創公司,目前處於早期預覽階段。他們讓自家 Agent 自主選擇攻擊目標(Agent 自己建議選麥肯錫,因為麥肯錫有公開的負責任揭露政策)、自主執行攻擊鏈,全程無人介入。
時間點上,這個事件發生在 2026 年 2 月底,距離 Lilli 上線已超過兩年。麥肯錫在收到通報後 24 小時內完成緊急修補,並於 3 月 9 日公開揭露。
整個 Disclosure 流程相當標準,但事件本身的含義遠比修補一個 SQL Injection 深遠得多。
3|深度解析(Deep Dive)
3.1 漏洞本身並不新鮮,新的是「誰找到它」的方式
SQL Injection 是資安界最古老的漏洞類型之一,但麥肯錫自己的內部掃描工具以及 OWASP ZAP 都沒有發現它。為什麼?
因為這個 SQL Injection 的觸發點不尋常——漏洞藏在 JSON 的「鍵名(key)」而非「值(value)」中,鍵名被直接拼接進 SQL 語句,而標準資安工具通常只測試值的注入,不會測試鍵名。
這正是 AI Agent 相對於傳統工具的核心優勢:它不跑 checklist,它觀察、推理、連結。Agent 透過 15 次盲注迭代,逐步從錯誤訊息中還原 query 結構,直到真實員工資料開始回傳。這個過程像一個資深滲透測試工程師在工作,只是速度快了幾個數量級。
So What:傳統靜態掃描工具的時代正在結束。能模擬「真實攻擊者思路」的自主 Agent,將重新定義滲透測試的標準。
3.2 被暴露的不只是資料,而是麥肯錫的「智識核心」
資料庫中存有 4,650 萬筆對話訊息、72.8 萬份文件(含 19.2 萬份 PDF、9.3 萬份 Excel)、5.7 萬個用戶帳號,以及 368 萬個 RAG 文件切片——那是數十年的麥肯錫專有研究、框架與方法論。
對一間靠「專有知識」收取高額顧問費的公司而言,這些 RAG 向量庫的外洩意義,遠比一般企業嚴重。競爭對手若能取得麥肯錫數十年累積的內部研究框架,等同於直接跳過了最難建立的知識護城河。
更嚴重的是對話內容。這些對話涵蓋策略、客戶案件、財務、M&A 活動——以明文形式儲存,無需驗證即可存取。這不只是 GDPR 合規問題,而是客戶機密的系統性外洩風險。
3.3 寫入權限 + Prompt 層 = 最危險的攻擊向量
資料外洩已經夠嚴重,但這次事件最值得深思的部分是 寫入權限對 Prompt 層的影響。
Lilli 的 System Prompt——也就是控制 AI 行為的核心指令——儲存在同一個可被 SQL Injection 寫入的資料庫中。 攻擊者可以在不改動任何程式碼、不觸發任何部署流程的情況下,直接修改 AI 的行為指令。
這帶來幾個具體威脅,都相當恐怖:
毒化建議:讓 AI 在財務模型或策略建議中夾帶偏差,顧問以為是自家工具,卻渾然不知
資料外洩管道:指令 AI 把機密資訊嵌入輸出,讓使用者在不知情下複製到對外文件
無跡可循的持久化:不像伺服器入侵會留下 Log,Prompt 修改沒有標準稽核軌跡——AI 只是「開始行為怪異」,但沒有人知道為什麼
So What:Prompt 已經成為攻擊者的首選新目標。但現實是,大多數企業的 Prompt 管理就像 2005 年的密碼管理——散落在各個 config 檔、資料庫欄位、API 呼叫裡,完全沒有對應的安全基礎設施。
3.4 AI Agent 已開始自主選擇攻擊目標,威脅格局正在重構
這次事件有一個細節很多人會忽略:攻擊目標(麥肯錫)是由 AI Agent 自主建議的,Agent 自行查閱了麥肯錫的公開負責任揭露政策,並引用 Lilli 的最新更新作為選擇依據。
這意味著什麼?這意味著「AI 自主選擇攻擊目標 → AI 自主發動攻擊 → 2 小時內完成全面入侵」已不是科幻場景,而是 2026 年 2 月實際發生的事情。
現在這個能力還掌握在白帽研究者手中,他們有道德約束。但相同的技術能力一旦流向惡意行為者,攻擊的規模化、自動化程度將超出現有防禦體系的應對能力。
5|Future Lin’s Take away(分析師觀點)
這篇文章讓我想到一個企業界普遍存在的認知落差:大多數決策者把「部署了 AI 工具」和「管好了 AI 工具」畫上等號。
Lilli 有嚴謹的 RAG 架構、有 12 種模型類型、有細緻的 Prompt 設計——但這些投資在一個沒有正確保護的 API 端點面前,全部歸零。
我認為這個事件最重要的教訓,不是「記得做 SQL Injection 防護」,而是「AI 系統需要一套全新的安全思維框架」。
傳統 IT 安全保護的是資料和程式碼。但 AI 系統多了一個新的高價值層:Prompt 層。這一層決定 AI 的行為,卻幾乎沒有對應的安全基礎設施——沒有 Git 版控、沒有存取稽核、沒有完整性監控、沒有 diff 記錄。這是一個巨大的盲點。
另一個我認為多數人忽略的角度是:AI 資安工具本身就是雙刃劍。
CodeWall 這次展示了 AI Agent 在白帽場景下的能力,但完全相同的技術也可以被惡意使用。當攻擊側有了 AI 加持,防守側如果繼續用人工為主的滲透測試,頻率和覆蓋率都將嚴重落後。
這是我推測 2026-2027 年資安市場會出現一波「AI vs AI」軍備競賽的核心理由——這是推測,但依據是攻守兩側技術能力的不對稱加速。
6|延伸閱讀 & 關鍵字
延伸閱讀主題:
Prompt Injection 攻擊全景:OWASP 已將 Prompt Injection 列為 LLM Top 10 風險之首,值得深讀其完整說明
AI Red Teaming 的崛起:微軟、Google、Anthropic 各自建立的 AI Red Team 方法論,與傳統滲透測試的差異
RAG 架構的安全設計:向量資料庫的存取控制、Chunk 層級的權限管理——這是目前業界討論最少、風險卻最高的區域
關鍵字 Hashtag: #AI資安 #PromptSecurity #LLM #企業AI #RedTeaming
7|CTA 結尾段落
這篇分析讓你意識到 AI 工具的「看不見的風險面」了嗎?企業 AI 平台的安全設計,將是 2026 年最被低估、卻最值得投入的議題之一。
📩 覺得這篇分析有幫助?歡迎分享給你的朋友。
🔔 訂閱《AI未來週報》,每週收到最精準的 AI 產業洞察 →

💬 想即時討論?加入 AI觀察日記 LINE 社群,輸入通關密語「Monday」→ https://reurl.cc/2Kxy94